
EPiC Challenge
In the field of affective computing, it is common to train models based on predictive measures using summary annotations. This means recording participants’ physiological annotations while they are experiencing a given affective state, which are reported after the emotional induction is complete.
This results in:
- Fewer data points to train our models.
- An oversimplified understanding of emotions that denies their natural dynamics.
Our research explores the untapped potential of capturing the continuous nature of emotions through the use of the Continuously Annotated Signals of Emotion (CASE) dataset, which provides 8 physiological measures and continuous annotations of valence and arousal.
This project is part of our participation in the Emotion Physiology and Experience Collaboration (EPiC) 2023 challenge.
Our work is a first benchmark of the performance of continuous predictive models on this dataset. Our results show significant improvements over existing benchmark models in specific challenge scenarios.
One of the main contributions of our study is the development and comparative analysis of predictive models on different affective dimensions. In particular, we found that models predicting arousal outperformed those predicting valence, consistent with established findings in the affective science literature.
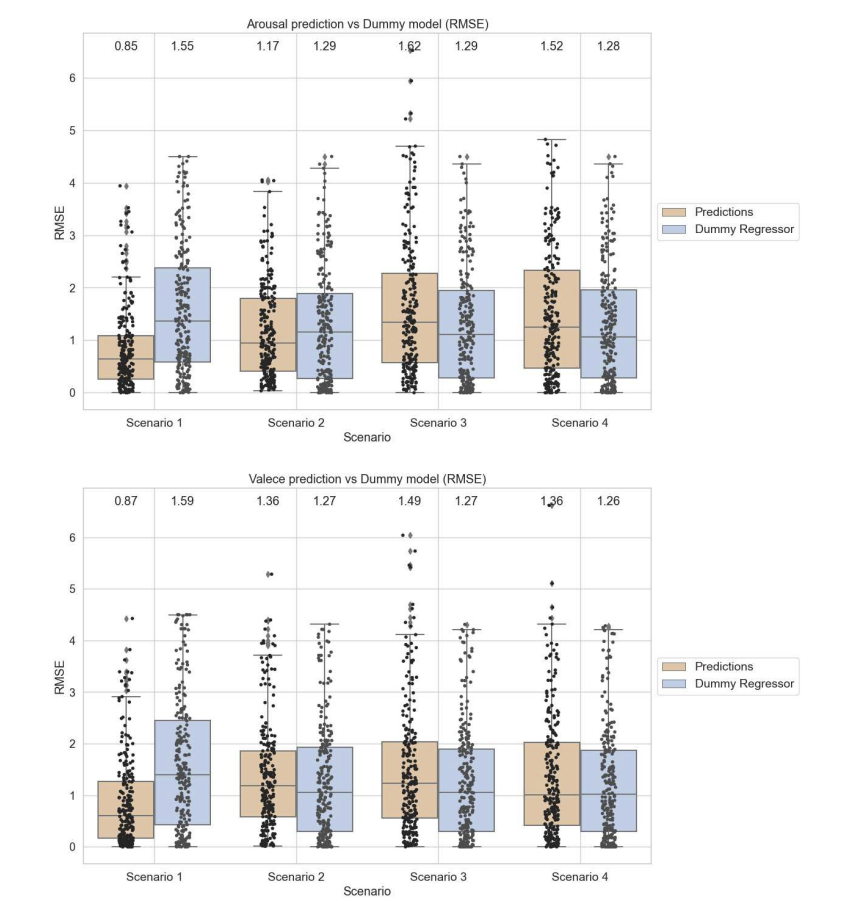 Fig. 1. Boxplots with scatter plot overlaid comparing the distribution of RMSE values across four different scenarios (scenario 1 to 4) for both the arousal and valence dimensions, with predictions in each scenario also compared to dummy predictions. Each subplot represents one dimension: arousal at the top and valence at the bottom. Each boxplot represents the interquartile range (IQR) with a line at the median. Overlaid scatter plots show the performance of each model.
Fig. 1. Boxplots with scatter plot overlaid comparing the distribution of RMSE values across four different scenarios (scenario 1 to 4) for both the arousal and valence dimensions, with predictions in each scenario also compared to dummy predictions. Each subplot represents one dimension: arousal at the top and valence at the bottom. Each boxplot represents the interquartile range (IQR) with a line at the median. Overlaid scatter plots show the performance of each model.
Moreover, our analysis revealed a crucial insight: predictive models that incorporate features of past data provide more informative results than those based on future data.
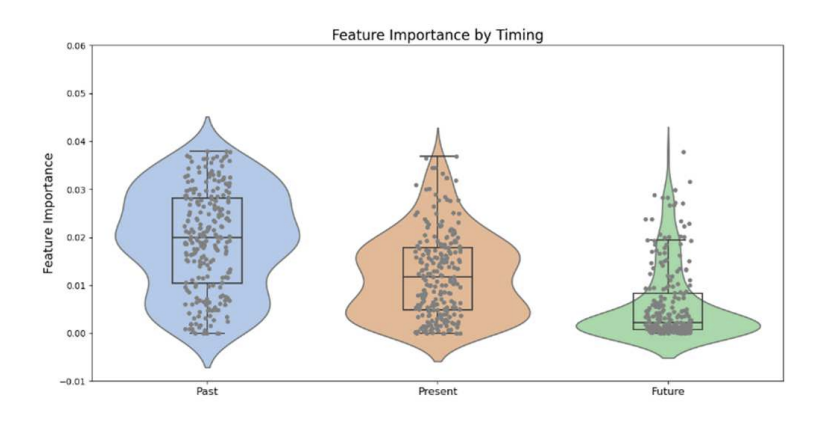 Fig. 2. Distribution of feature importance for the 240 models trained in scenario 1, It illustrates the distribution of feature importance by partitioning the window into past (pre-annotation), present (during annotation), and future (post-annotation) information. Boxplots, violin plots and scatterplots are used to visualize the feature importance distributions.
Fig. 2. Distribution of feature importance for the 240 models trained in scenario 1, It illustrates the distribution of feature importance by partitioning the window into past (pre-annotation), present (during annotation), and future (post-annotation) information. Boxplots, violin plots and scatterplots are used to visualize the feature importance distributions.
This suggests a fundamental role for physiological activity as a precursor to affective experience and its subsequent annotation. This finding is fundamental to understanding the temporal dynamics of emotion.
…
This project was part of a paper presented at the International Conference on Affective Computing and Intelligent Interaction 2023 (ACII 2023), hosted by the MIT Media Lab, in the EPiC workshop.
You can download a PDF copy of the presented paper here.